This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
Cite this article
Whittle J, Borgo R, Jones MW.2016. Implementing generalized deep-copy in MPI. PeerJ Computer Science2:e95https://doi.org/10.7717/peerj-cs.95
Abstract
In this paper, we introduce a framework for implementing deep copy on top of MPI. The process is initiated by passing just the root object of the dynamic data structure. Our framework takes care of all pointer traversal, communication, copying and reconstruction on receiving nodes. The benefit of our approach is that MPI users can deep copy complex dynamic data structures without the need to write bespoke communication or serialize/deserialize methods for each object. These methods can present a challenging implementation problem that can quickly become unwieldy to maintain when working with complex structured data. This paper demonstrates our generic implementation, which encapsulates both approaches. We analyze the approach with a variety of structures (trees, graphs (including complete graphs) and rings) and demonstrate that it performs comparably to hand written implementations, using a vastly simplified programming interface. We make the source code available completely as a convenient header file.
Introduction
Message passing is an established communication paradigm for both synchronous and asynchronous communication in distributed or parallel systems. Using MPI with object orientation is not always an easy task, while control on memory locality and data distribution represent extremely valuable features, dealing with the ever growing and sophisticated features of OO languages can be cumbersome.
This problem is particularly challenging for data structures employing abstractions (e.g., inheritance and polymorphism) and pointer indirection, since transferring these data structures between disjoint hosts requires deep copy semantics. For user defined objects MPI adopts shallow copy semantics, whereby default copy constructors and assignment operators perform shallow copies of the object leaving memory allocation, copy, and de-allocation to be the responsibility of the programmer, not the implementation. A similar policy is applied to MPI objects, represented as handles to opaque data that cannot be directly copied. Copy constructors and assignment operators in user defined objects that contain an MPI handle must either ensure to invoke the appropriate MPI function to copy the opaque data (deep copy) or use a reference counting scheme that will provide references to the handle (reference counted shallow copy). Shallow copy is acceptable for shared-memory programming models where it is always legal to dereference a pointer with the underlying assumption that the target of member pointers will be shared among all copies. Users often require deep copy semantics, as illustrated in Fig. 1, where every object in a data structure is transferred. Deep copy requires recursively traversing pointer members in a data structure, transferring all disjoint memory locations, and translating the pointers to refer to the appropriate device location also referred to as object serialization or marshalling, commonly used for sending complex data structures across networks or writing to disk. MPI has basic support for describing the layout of user defined data types and sending user-defined objects between processes (Message Passing Interface Forum, 2014).
Figure 1: An example of a structure that requires deep copy semantics.
Arrows represent pointer traversals to disjoint regions of memory.
The directives we propose provide a mechanism to shape and abstract deep copy semantics for MPI programs written in C++. Along with elegantly solving the deep copy problem, this mechanism also reduces the level of difficulty for the programmer who only needs to express the dependencies of an object type, rather than explicitly programming how and when to move the memory behind pointers.
As a motivating example, we show that comparable performance can be achieved when using a simple and generic algorithm to implement deep copy compared to hand coded native MPI implementations. The main contributions of this work are:
We introduce the MPI Extension Library (MEL), a C++ header-only wrapper around the MPI standard which aims to give a simplified programming interface with consistent type-safety and compile time error handling, along with providing efficient implementations of higher level parallel constructs such as deep copy.
As a part of MEL, we provide generic implementations of deep copy semantics that can be easily applied to existing code to enable complex structured data to be deep copied transparently as either a send, receive, broadcast, or file access operation with minimal programmer intervention. The latter can also be used for the purpose of check-pointing when writing fault tolerant MPI code.
Related Work
Message passing as a style of parallel programming enables easy abstraction and code composition of complex inter-process communications. Existing MPI interfacing libraries (McCandless, Squyres & Lumsdaine, 1996; Huang et al., 2006; Boost-Community, 2015) by default rely on the underlying standard shallow copy principle, where data contains no dependencies of memory outside the region directly being copied; and that where dependencies do exist that they are explicitly resolved by the programmer using subsequent shallow copies. However, this simplified model of communication comes at the cost of having to structure computations that require inter-process communication using low-level building blocks, which often leads to complex and verbose implementations (Friedley et al., 2013). Similar systems, such as the generic message passing framework (Lee & Lumsdaine, 2003) resolve pointers to objects, but do not follow dynamic pointers (data structure traversal) to copy complete complex dynamic structures possibly containing cycles.
MPI works on the principle that nothing is shared between processes unless it is explicitly transported by the programmer. These semantics simplify reasoning about the program’s state (Hoefler & Snir, 2011) and avoid complex problems that are often encountered in shared-memory programming models (Lee, 2006) where automatic memory synchronization becomes a significant bottleneck.
Autolink and Automap (Goujon et al., 1998) work together to provide similar functionality. Automap creates objects at the receiver. Autolink tags pointers to determine whether they have been visited or not during traversal. The user must place directives in their code and carry out an additional compilation step to create intermediate files for further compilation. Extended MPICC (Renault, 2007) is a C library that converts user-defined data types to MPI data types, and also requires an additional compilation. It can automate the process, but also in some cases requires user input to direct the process. Tansey & Tilevich (2008) also demonstrate a method to derive MPI data types and capture user interaction via a GUI to direct the marshalling process.
Autoserial Library (GNA, 2008) gives a C++ interface for performing serialization to file as binary or XML; or to a raw network socket as binary data. Their library also offers a set of convenience functions for buffering data to a contiguous array with MPI communications to move the data. Their method makes extensive use of pre-processor macros to generate boilerplate code needed for deep traversal of objects. For MPI, this library only handles the use case of fully buffered deep copy in the context of MPI_Send and MPI_Recv communications.
OpenACC (Beyer, Oehmke & Sandoval, 2014) tackles the deep copy problem in the context of transferring structured data from host machines to on node hardware such as GPUs and Accelerators. Their approach is based on a compiler implemented #pragma notation similar to OpenMP while our method is implemented as a header only template library.
TPO++ (Grundmann, Ritt & Rosenstiel, 2000) requires serialize and deserialize functions to be defined. The paper highlights good design goals which we also follow in this work.
Compared to the above approaches, we place much lighter requirements on the user and do not require additional signposting (usually implemented as preprocessor macros wrapped around variable declarations) that other methods require. We do not require an additional compilation step or GUI compared to the above as will be demonstrated in the following sections. We also provide an analysis of our approach. We explicitly demonstrate and analyze our approach on a wide variety of complex dynamic data structures. Our analysis shows that our approach has low time and memory overhead and also requires less user direction to achieve deep copy. It provides this extra functionality at no loss of performance over hand coded approaches. We avoid the in place serialize that some approaches utilize, resulting in our approach having a low memory overhead. We also evaluate our methods in comparison to Boost Serialization Library (Cogswell, 2005) and demonstrate that Boost introduces a performance penalty which our method avoids. Boost also requires more intervention from the user/programmer to achieve the same capability. Therefore, the main benefit of our approach over others is that it is a true deep copy approach where the user only has to pass in the root object/node of the data structure.
In CHARM++ (Kale & Krishnan, 1993; Miller, 2015) messages are by default passed by value, however CHARM++ provides support for deep copy via definition of serialization methods for non-contiguous data structures. It is a user task to define the proper serialization methods including the explicit definition of memory movement and copy operations. If the serialization methods are implemented correctly for a user-defined type, a deep copy will be made of the data being serialized. CHARM++ distinguishes between shared-memory and distributed-memory scenarios, where shared-memory data within a node can be directly passed by pointer. The programmer must explicitly specify the policy to be adopted by indicating if the data should be conditionally packed or not. Conditionally packed data are put into a message only when the data leaves the node. In an MPI environment processes within the same node do not share a common address space making such an optimization unavailable.
Generally the more desirable solution is to avoid deep copy operations to maintain efficiency in message transmission. This is straightforward to achieve by converting user-defined types with pointer members to equivalent user-defined types with statically-sized arrays. This approach of restructuring and packing a data structure is often used by shared-memory programming paradigms where structures with pointers are manually packed and unpacked across the device boundary to reduce transfer costs for data structures used on the device.
When memory isolation (e.g., avoid cross boundary references) is not a requirement other approaches might be possible. For operations executed within sequential or shared memory multi-core processors, hardware can be used more efficiently by avoiding deep copy operations and rely instead on pointer exchange. This requires messages to have an ownership transfer semantics with calls to send (pass) ownership of memory regions, instead of their contents, between processes (Friedley et al., 2013). In the context of the present work, we do not focus on ownership passing but on the traditional approach of refactoring code. MEL provides an efficient and intuitive alternative to implementing object packing by hand. Porting an object type to use MEL deep copy only requires adding a member function to the type containing directives that describe the dependencies of the type. In this case, the additional effort to rewrite data structures to allow communication using the standard MPI shallow copy principles is much larger, making refactoring an application to avoid deep copy an undesirable solution.
Deep copy semantics are not only relevant when dealing with inter-process communication. When recovering from process or node failure in fault tolerant MPI, applications often incur problems very similar to the ones dealt by deep copy operations. Fault tolerance plays an important role in high performance computing applications (Herault & Robert, 2015) and significant research has focused on its development in MPI (Gropp & Lusk, 2004; Vishnu et al., 2010; Bouteiller, 2015). While the library itself does not provide explicit fault-tolerance support, MPI can provide a standard and well-structured context for writing programs that exhibit significant degrees of fault tolerant behavior. Several approaches have been investigated in literature to achieve fault tolerance in MPI (Gropp & Lusk, 2004; Laguna et al., 2014), with check-pointing being one of the most commonly used compared to more sophisticated approaches involving direct manipulation of the MPI standard to support fault tolerance (Fagg, Bukovsky & Dongarra, 2001; Fagg & Dongarra, 2004), or modifying semantics of standard MPI functions to provide resilience to program faults.
In check-pointing, a process will periodically cache its work to disk so that in the event of a crash or node failure, a newly spawned process can load back the last saved state of the failed process and continue the work from there. When the data a process is dependent on is deep in structure, the implementation challenges associated with reading and writing the data to disk are the same ones encountered when handling the communication of such types. MEL provides support for fault-tolerance by leveraging deep copy semantics to transparently target file reads and writes in the same manner it handles the sending and receiving of inter-process communications.
When to Use Deep Copy
It is important that programmers be aware of the dangers of shallow-copying deep types without also resolving any dependencies of that type. For example, if an object contains a pointer and is copied by its memory footprint to another MPI process the value of the contained pointer on the receiver is now dangling and accessing the pointed to memory erroneous. Listing 1 shows an example of performing such an MPI shallow-copy when a deep copy was needed.
While accessing the pointed to memory is invalid, if we declare as a rule that if a pointer is not allocated it will be assigned to nullptr (and we strictly adhere to this rule), we can use the value of the dangling pointer to determine if an allocation needs to be made and data received on the receiving process. Listing 2 gives a corrected example of Listing 1, by deep copying a struct containing a pointer safely using native MPI commands.
If an object which implements its own memory management through copy/move constructors and assignment operators, such as std::vector, is used, heap corruption can occur in a manner that can be difficult to debug. An example of this is shown in Listing 3. If a std::vector is copied by footprint its internal pointer, just like the raw pointer previously, is no longer valid. The vector class works on the assumption that its internal pointer is always valid, and that it needs to be de-allocated or re-allocated if any of the assignment, resize, or destructor functions are called. If the vector goes out of scope and its destructor is called the incurring segfault will often not be caught correctly by a debugger and the error will be reported “nearby,” leaving the programmer to hunt down the true source of the error. Short of using the C++ placement-new operator to force the vector to be recreated without calling its destructor there is no way of “safely” recovering in this situation.
Buffered vs. non-buffered
So far we have discussed methods for deep copying object types by recursively traversing the data-structure and performing discrete message operations to resolve each dependency. While often small there is a performance cost associated with beginning and ending a communication between processes, and this cost is exacerbated when communication occurs between processes on different physical nodes connected by a network interface. In many cases it is beneficial to pack a deep structure into a contiguous buffer on the sending process and to transport it as a single communication, the buffer can then be received and unpacked to reconstruct the target data structure. Listing 4 demonstrates a variant on Listing 2 where data is packed into a buffer before being transported and unpacked on the receiving process.
While buffered deep copy enables greater performance when communicating large structures made up of many small objects between processes, this speed comes at the cost of increased code complexity and limitations on the size of data that can be transferred. In the scenario where the data to be deep copied occupies more than half of the available system memory buffering into a contiguous buffer is no longer applicable as there is no remaining space in memory to allocate the buffer. Additionally, for programs that make many small allocations and de-allocations during normal execution system memory can become fragmented, leading to a situation where there is more than enough available memory to allocate the buffer but it is split up in many small pieces meaning no one contiguous allocation can be made. In these scenarios there is no alternative but to perform a non-buffered deep copy to move the data.
Buffering may also perform worse than non-buffered methods when the data to be deep copied consists of a small number of large objects, such as a struct containing several pointers to large buffers. In this case it may be detrimental to force the local copying of the large buffers into a single message only to unpack them on the receiving process when it would have been faster to transport them separately while taking the hit on the overheads associated with setting up multiple communications.
MEL–The MPI Extension Library
MEL is a C++11, header-only library, being developed with the goal of creating a lightweight and robust framework for building parallel applications on top of MPI. MEL is designed to introduce no (or minimal) overheads while drastically reducing code complexity. It allows for a greater range of common MPI errors to be caught at compile-time rather than during program execution when it can be far more difficult to debug.
A good example of this is type safety in the MPI standard. The standard does not dictate how many of the object types should be implemented leaving these details to the implementation vendor. For instance, in Intel MPI 5.1 MPI_Comm objects and many other types are implemented as integer handles, typedef intMPI_Comm, to opaque data that are managed by the MPI run-time. A drawback with this approach is it causes compile time type-checking of function parameters to not flag erroneous combinations of variables. The common signature MPI_Send(void*, int, MPI_Datatype, int, int, MPI_Comm) is actually seen by the compiler as MPI_Send(void*, int, int, int, int, int), allowing any ordering of the last five variables to be compiled as valid MPI code, while potentially causing catastrophic failure at run-time. In contrast, Open MPI 1.10.2 implements these types as structs which are inherently type-safe. With MEL we aim to:
Remain true to the underlying design of MPI, by keeping to an imperative function interface that does not fundamentally change the way in which the programmer interacts with the MPI run-time.
To provide a type-safe, consistent, and unified function syntax that allows distributions of MPI from all vendors to behave in a common and predictable way at both compile-time and run-time.
To be soluble, allowing the compiler to remove the abstractions MEL provides to achieve the same performance as native MPI code.
To be memory efficient by minimizing the use of intermediate buffers whenever possible.
To make use of modern C++ language features and advanced template meta programming to both ensure correctness at compile-time and to generate boiler-plate values that programmers have to provide themselves with native MPI code.
To give higher-level functionality that is not available from the MPI standard such as deep copy Semantics (our focus in this paper).
MEL deep copy
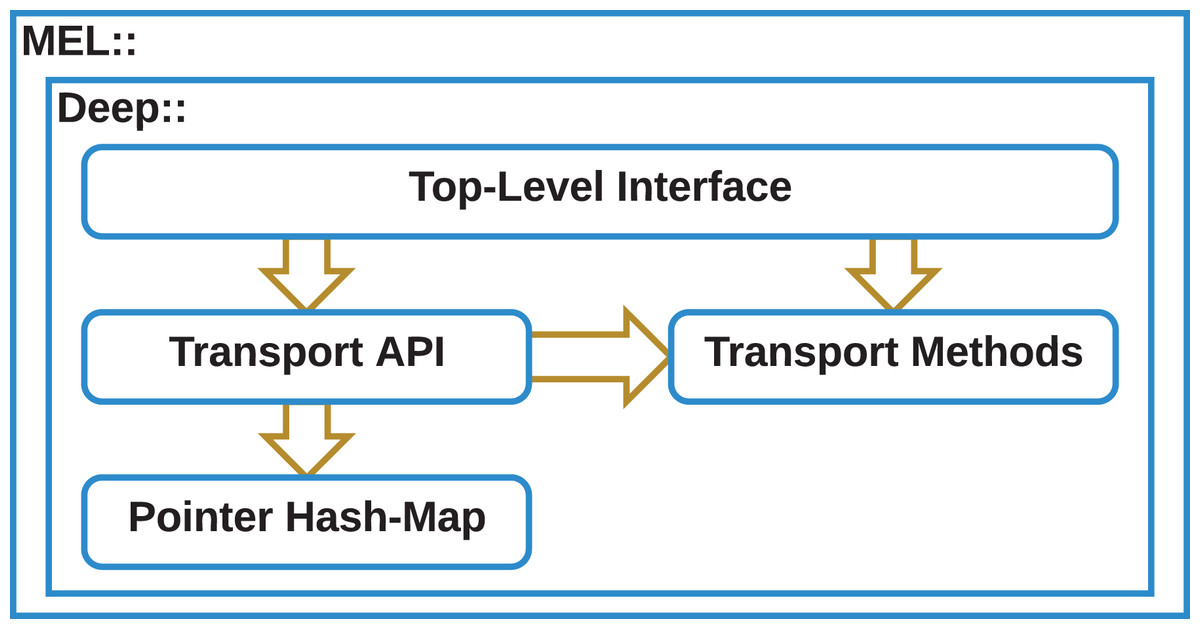
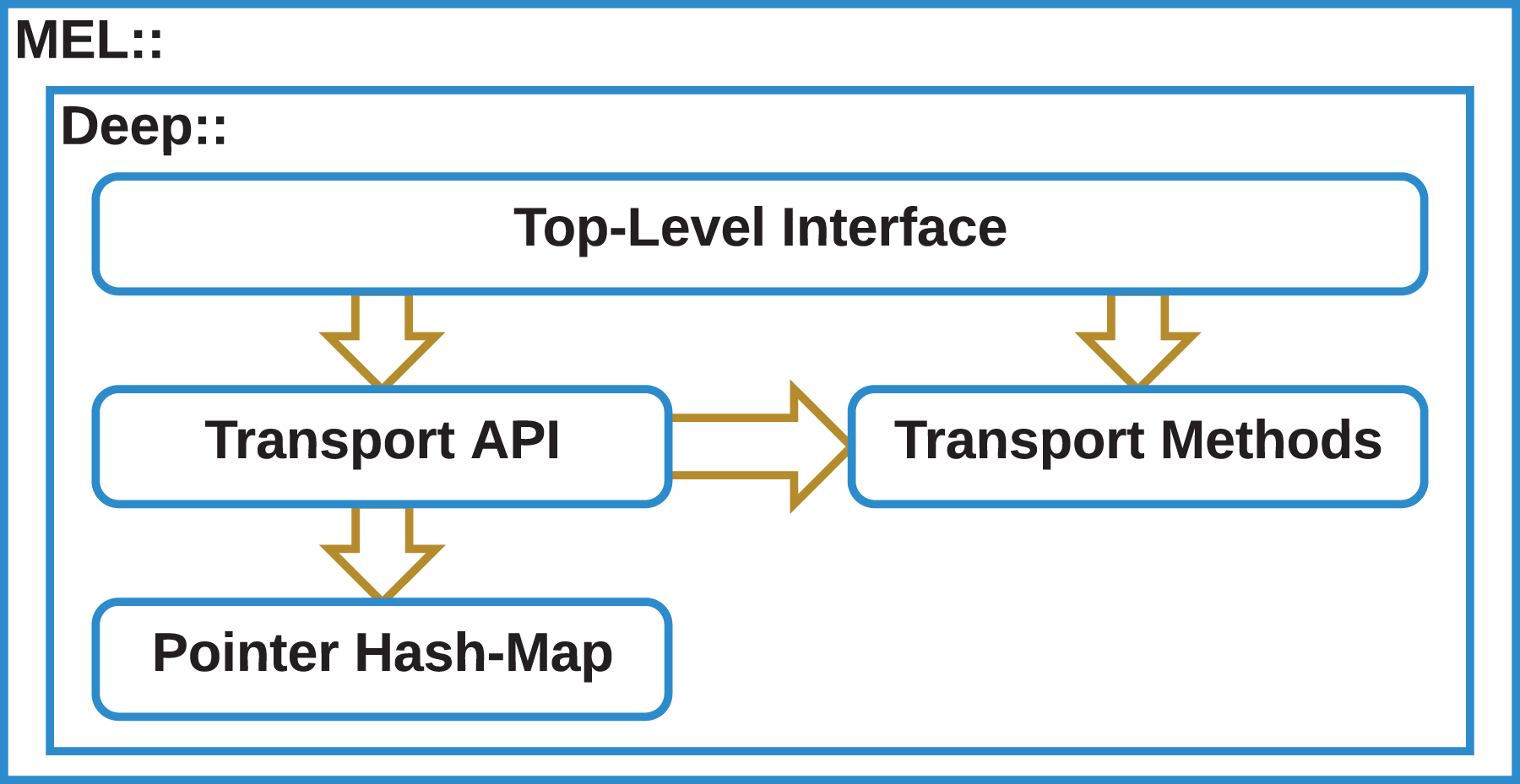
Our algorithm is implemented in four parts, a top-level interface of functions for initiating deep copy as send/receive, broadcast, or file-IO operation; a transport API of functions that describe how data is to be moved within a deep copy operation, a set of transport methods that describe generically how to move a region of memory; and a hash-map interface for tracking which parts of the data structure have already been traversed. Figure 2 shows the architecture of our algorithm.
Figure 2: MEL deep copy architecture.
In order to ensure correct memory management for deep structures the user must adhere to:
Unallocated pointers are initialized to nullptr.
Dynamic Memory must be allocated using MPI_Alloc_mem and freed using MPI_Free_mem, or the equivalent MEL calls:
Pointers refer to distinct allocations. E.g. It is erroneous to have an allocation of the form char*ptr = new char[100] in one object, and to then have a weak-pointer into the array in subsequent objects: char*mySubPtr = &ptr[50]. In these situations, it is best to store integer offsets into the array, rather than the pointer address itself.
Top-Level interface
The top-level interface for our algorithm (Listing 5) consists of functions for initiating a deep copy as a send, receive, broadcast, or file access operation on a templated pointer (T*), a pointer-length pair (T*, len), an object reference (T&), or an STL container (std::vector<T>&, std::list<T>&). In the case of receiving methods (Recv, Bcast, and FileRead) the len parameter can either be passed by reference so that it can be modified to reflect the number of elements that were actually received, or captured from an integer literal or constant variable to provide a run-time assertion whether the correct number of elements were received. All methods are blocking and do not return until the entire data-structure has been transferred.
Buffered variants of the top-level interface initiate a local deep copy to a contiguous buffer on the sender, this buffer is then sent as a single transport to the receiving processes where it can be unpacked. By decreasing the number of MPI communications or file accesses needed to transfer a deep structure significant reductions in latency can be achieved, at the cost of added memory overhead from packing and unpacking data before and after transport. In general, large structures of small objects (i.e. a tree with many nodes that are small in memory) benefit most from buffering while smaller structures of large objects (i.e. a struct containing large arrays) tend to benefit from non-buffered transport.
Another motivating reason for providing a non-buffered mechanism for deep copy is the scenario where the deep structure occupies more than half of the available system memory. In such cases it is not possible to make a single contiguous allocation large enough to pack the structured data. An example of where this can happen is the use of MPI to distribute work to banks of Intel Xeon Phi Coprocessors which are exposed to the host system via a virtual network interface. While such hardware provides a large number of physical processor cores (60) on card memory is reduced (8–16 GB). On larger systems with more available memory this is less likely to occur although the use of non-buffered methods may still be desirable for the reasons outlined above; and in any case, achieving low memory overhead is good practice.
Detecting objects that require deep copy
Determining whether a given object is “deep” or not is performed at compile time using C++ template meta-programming to detect the presence of a member function of the form
template<typenameMSG> void DeepCopy(MSG &msg)
that describes how to resolve the dependencies of a given object type. The template parameter MSG is a shorthand for MEL::Deep::Message<TRANSPORT_METHOD, HASH_MAP> where TRANSPORT_METHOD and HASH_MAP are types satisfying the constraints described in sections Transport Method and Hashing Shared Pointers, respectively. A detailed example of the method used to detect the presence of a matching member function is given in section Detecting the Deep Copy Function using Template Meta-Programming.
The use of template meta-programming in C++ allows for the complete set of possible copy operations needed to transport a structure to be known at compile time, allowing the compiler to make optimizations that might otherwise not be possible if inheritance and virtual function calls were used. Template programming also opens up the future possibility of using more advanced C++ type_traits such as std::is_pod<T> (is-plain-old-data) and other similar type traits to help make informed decisions about how best to move types automatically at compile time.
Because we use the same function for sending/receiving, buffered/non-buffered, and for point-to-point/collective/ or file access communications we make use of a utility type, Message, that tracks which operation is being performed and where data is coming from or going to. The message object is created internally when one of the top-level functions is called and remains unmodified throughout the deep copy.
Message Transport-API
The deep copy function declares to our algorithm how data dependencies of a type need to be resolved in order to correctly rebuild a data structure on the receiving process. To keep the definition of this function simple the Message object exposes a small API of functions (Listing 6) that abstract the details of how data is sent and received between processes.
Listing 7 gives an example usage of the Message transport API to move a complex data-structure. All of the functions provided work transparently with both deep and non-deep types, with the exception of Message::packVar which is intended only for the transport of deep types as non-deep member variables will be transported automatically. By comparison, Boost Serialization Library requires that all types except for language defined base types (i.e. int, bool, double) provide serialization functions regardless of whether they contain deep members, and that all member variables within the type (including non-deep members) are explicitly registered with the archive object.
An example copy
In essence, the deep copy algorithm works by both sending and receiving processes entering a message loop or handshake with one another where they both expect to keep sending and receiving data until the entire structure has been transferred. The sending process determines how much data is to be sent, and this information is conveyed to the receiving processes transparently in such a way that when a receiving process determines there is nothing left to receive the sending process has returned.
Listing 8 shows an example of using the deep copy function to move an array of non-deep objects. Because the type, int, does not provide a member function for deep copy the footprint of the array is sent in a single MPI message. On the receiving process memory is allocated into the pointer provided and the data is received.
An example of moving an array of structs containing pointers to dynamically allocated memory is given in Listing 9. In order to correctly reconstruct the data on receiving processes a deep copy function has been implemented which tells the algorithm to copy a char array containing len elements. Because the type has a deep copy function the receiving processes will allocate the memory for the array of structs and copy the footprint of the array as a single contiguous chunk resulting in non-deep member variables being transferred automatically. The receiving process makes the necessary allocations to receive its dependencies. Both sending and receiving processes will then loop over each element in their array and call the objects deep copy function to resolve its data dependencies. If the struct contained variables which themselves required a deep copy the algorithm would recurse on them until all dependencies are resolved. In this simple case, however, the struct contains a char array which does not require a deep copy and as such the sub-array is transferred by allocating the needed memory and copying the entire sub-array as one contiguous chunk, as in Listing 8.
Transport method
The Message object represents how our algorithm traverses the deep structure and ensures that both sending and receiving processes independently come to the same conclusion on what order objects are traversed in with minimal communication. This traversal order is independent of, and identical for all deep copy operations. Because of this we template the Message object on a type that represents the specific nature of the data transportation we want to perform (i.e. Message<TransportSend> to perform deep copy as an MPI_Send communication), allowing the same traversal scheme to be reused.
As a part of our implementation we provide transport methods for a wide variety of data movement scenarios:
Adding additional transport methods is as simple as implementing a class with a public-member function of the form
that describes how to move a region of memory, and a public-static-member variable staticconstexprboolSOURCE which tells the compiler whether or not this is a sending or a receiving transport method. This boolean is important as it tells the Message object whether or not it needs to make allocations as it traverses the deep structure. The transport method should also store any state variables need to maintain the transport over the duration of the deep copy. Such state variables may be but are not limited to an MPI communicator and process rank, a file handle, or a pointer to an array used for buffering.
Hashing shared pointers
When considering large structured data containing duplicate pointers the method used to track which parts of the structure have already been transported can have a significant impact on the traversal time. A hash-map is a natural choice for representing an unordered map between two pointers as it is efficient for random access lookups and insertions.
As with the transport method, the Message object is also templated on the hash-map to use for pointer tracking, namely Message<TRANSPORT_METHOD, HASH_MAP = MEL::Deep::PointerHashMap>. This allows for the user to provide an adapter to their own implementation of a hash-map specifically optimized for pointers or to provide an adapter type to a third-party hash-map implementation.
To use a custom hash-map with any of the top-level functions simply override the default template parameter when initiating a deep copy operation. E.g. MEL::Deep::Send<int, MyCustomHashMap>(ptr, len, dst, tag, comm); where MyCustomHashMap exposes public-member functions of the form:
These functions are templated on the pointer type, T*, so that user provided hash-map adapters are able to use this extra type information to optimize hashing if needed.
External deep copy functions
So far we have discussed the use of deep copy functions and the transport API in cases where the deep copy function was a local member function of the type being considered. In some use cases, a structure may be defined in headers or libraries that cannot be modified easily (or at all). In such cases, we still would like to be able to define the deep copy semantics for the type without directly modifying its implementation. To enable this, we provide an overload of all the functions in the transport API and top-level interface that take an additional template parameter that is a handle to a global-free-function of the form
that takes by reference an instance of the object to transport and a Message object to perform the deep copy.
Listing 10, shows the usage of external free deep copy functions with types needing deep copy. StructB contains an internal member function for performing deep copy, while StructA does not. Passing an instance of StructA to the top-level interface will result in incorrect results as its dependencies will not be resolved. By implementing a global-free-function that defines the deep copy requirements of StructA, we can then tell the top-level interface to explicitly use that function to resolve external dependencies of the type. If we provide an external free function for StructB which already has an internal deep copy function, the internal function is ignored and the free function explicitly given is used.
The same rules apply for providing external free functions to the transport API. Listing 11, shows an example of this, where once again StructA is a deep type that does not provide an internal deep copy function. StructC is also deep and contains a std::list of StructA. If the deep copy function of StructC simply calls the ampersand operator or Message::packSTL function (Listing 11, lines 15, 16) to transport the std::list then the instances of StructA will be transported incorrectly as a non-deep type. In the same manner as with the top-level interface the free function to use to deep copy StructA is given explicitly to Message::packSTL so that it can correctly resolve the dependencies of the deep structure.
The option to use external deep copy functions gives our method flexibility when we need to add deep copy semantics to code that cannot be directly, or easily modified. However, this does not mean it will always be applicable as it requires intimate and low-level knowledge of the object’s internal implementation and methods of allocation.
MEL Implementation Details
In the following section we provide a detailed discussion of the implementation of the MEL deep copy algorithm.
Detecting the deep copy function using template meta-programming
To detect whether the type under consideration contains a deep copy function we make use of SFINAE (Substitution Failure Is Not An Error) to create a compile-time boolean test for the existence of a member function with the desired signature. We encapsulate the usage of this method into a templated shorthand that uses std::enable_if to give us a clean and concise method for providing function overloads for deep and non-deep types.
Listing 12, shows an implementation of the technique used to conditionally detect member functions of template types at compile time. The overloads of voidsomeFunc(T &obj) for when T is or is not a type with a deep copy function allows us specialize our implementation for deep types while allowing them to share identical function signatures.
Transport-API implementation
Next we describe the implementation of the transport API which specifies the traversal order our algorithm uses when performing deep copy.
Message::packVar
The Message::packVar function will call the deep copy function of the given variable to resolve its dependencies. This function works on the assumption that local member variables of the object have already been transported when the parent object was traversed. It is for this reason that Message::packVar is only defined for deep types, as a non-deep type will have been transported automatically with the parent. In all of the following listings for the implementations of the transport API the overloads for non-deep types have been omitted for space.
Message::packPtr
When transporting dynamically allocated memory special care must be taken to correctly allocate memory on the receiving processes. Listing 14 shows the implementation of Message::packPtr for deep types. This function offloads its work to the transportAlloc helper function of the Message object. On receiving process, transportAlloc will make an allocation of len elements of the given type before receiving the data. On the sending process, transportAlloc is identical to transport and simply moves the requested data. For a deep type, Message::packPtr will then loop over all the received elements and call their deep copy functions to resolve any dependencies.
Message::packSharedPtr
In complex structured data there is often a requirement for data to be self referencing. That is, one part of the deep structure may be pointed to from multiple other points within the structure. In these situations, a naïve deep copy algorithm would traverse the shared object within the structure multiple times allocating a unique copy of it with each visit. If the shared object is deep itself and points to one of its ancestors within the structure, then the deep copy algorithm will become stuck in an infinite cycle within the data, allocating new memory with each loop. To avoid this and to allow complex self-referential data to be transported, we provide the Message::packSharedPtr function shown in Listing 15. This method checks the given pointer against a hash-map of type (pointer → pointer) to determine if the pointed to memory has already been transported.
During deep copy, the first time a shared pointer is passed to Message::packSharedPtr on both the sending and receiving processes, it is transported in the same manner as in Message::packPtr by calling transportAlloc. On the sending process, the pointer is then inserted into the hash-map so it can be ignored if it is visited again. On the receiving processes, the call to transportAlloc will have caused the dangling pointer from the sender to have been overwritten with the newly allocated pointer. This new pointer is inserted into the hash-map with the original (dangling) pointer as the key, so that next time the receiver is asked to transport the same dangling pointer it can simply lookup and return the existing allocation.
When a shared pointer that has already been visited is passed to Message::packSharedPtr and it is found within the hash-map then sending process can simply return as no memory needs to be transported; the receiving process uses the dangling pointer passed to it to retrieve the valid pointer that was previously allocated and transported the last time the shared pointer was visited. All interaction with the hash-map is performed through the pointerMap.find and pointerMap.insert functions of the Message object. These functions are further discussed in Section Hash-map implementation.
A nice property of this scheme is that the hash-map is never communicated and is constructed independently on both the sending and receiving processes. This means that for non-buffered communications the sender and receiver can traverse the structure in parallel (lock-step), and for buffered communications or buffered/non-buffered file-access the processes can traverse the structure independently.
Message::packSTL
As part of the transport API, we provide helper functions for moving common C++ STL containers. Listing 16 shows the implementation of Message::packSTL for C++ std::vector’s of both deep and non-deep types. This is very similar to the implementation of Message::packPtr discussed previously with the slight difference that instead of making a new allocation on the receiving processes via transportAlloc we instead repair the internal pointer of the given std::vector by calling the placement-new operator to recreate the vector in place (as discussed in Listing 3). The implementations of Message::packSTL for other STL containers is conducted in the same way and is omitted here.
Finally, we provide a set of functions to simplify the implementation of the top-level interface. Recall that Message::packVar is only defined for deep types and assumes that the object’s footprint is always transported with the parent object. This is not the case for the top-level functions as no parent has been transported; in this case we must explicitly transport the object footprint regardless of whether it is deep or not.
A similar scenario occurs for pointers passed to the top-level interface. In order to avoid duplicating all of the top-level functions to account for whether the root pointer is shared we always insert it into the hash-map as this is a small constant overhead that does not affect performance. Recall from the implementation of Message::packSharedPtr that on the receiving processes the dangling pointer from the sender is used as the key into the hash-map. Because of this, for the root pointer we must explicitly transport the address-value of the pointer from the sender to the receiving processes so they can insert it into their hash-maps.
Finally, when considering STL containers passed to the top-level interface, receiving processes cannot query .size() of the container as its footprint was not previously transported. Instead, we explicitly transport the size of the container and call .resize() on the receiving processes.
Transport method implementation & usage
A transport method is a class which provides a single public-member function of the form
which defines how to move len objects of type T from a given pointer ptr. Listing 18 shows the implementation of the TransportSend transport method, which defines how to move data using a discrete MPI_Send for each transport. An instance of a transport method carries any state needed to represent the data movement over the duration of the deep copy. In the case of TransportSend the state needed to represent the transfer are the MPI rank of the destination process, a tag to use for the communication, and the MPI communicator over which the data will be transferred. For other transport methods the state may be a file handle, or a pointer to an array used for buffering.
Listing 19 shows the implementation of one of the top-level interface functions for performing deep copy as an MPI_Send operation. A Message<TransportSend> object is instantiated, and the parameters from the function are transparently forwarded to the instance of the transport method within the Message object using std::forward<Args>(args). After creating the message object the pointer to the deep structure can be transported by calling Message::packRootPtr from the transport API.
When performing a buffered deep copy the data is first packed into a contiguous buffer on the sending process before being transported as a single operation to the receiving processes where the data can then be expanded back into the deep structure. Listing 20 shows the implementation of BufferedSend and BufferedRecv which make use of the TransportBufferWrite and TransportBufferRead transport methods.
The last parameter to buffered transport methods on sending processes is an integer value representing the byte size of the contiguous buffer to use for packing the deep structure. If this value is omitted an overloaded version of the function computes the upper-bound of the buffer size needed by calling MEL::Deep::BufferSize before forwarding its parameters to the main function overload.
Note that on the sending process for a buffered transport that msg.getOffset() is used as the length parameter when transporting the buffer (Listing 20, line 19) and not the bufferSize parameter. This means that if the sender blindly requests a large buffer because it does not know the size of the deep structure exactly, but only a part of the buffer is filled, only the used part of the buffer will be transported to the receiving processes. In the scenario where the buffer size given was not large enough to complete the deep copy, a run-time assertion occurs.
Hash-Map implementation
The Message object is templated on a hash-map type that exposes public-member functions of the form:
This allows the user to provide an implementation of a hashing scheme optimized for pointers or to provide an adapter to a third-party hash-map implementation. One of the goals of MEL is to be portable and to not introduce external dependencies on the users code; because of this, our default hash-map implementation (Listing 21) is simply a wrapper around a std::unordered_map container between two void pointers.
Benchmarks
For benchmarking we used the Swansea branch of the HPC Wales compute cluster. Nodes contain two Intel Xeon E5-2670 processors for a total of 16 physical cores with 64GB’s of RAM per-node, connected with Infiniband 40 Gbps networking. Benchmarks were run using Intel MPI 4.1 and compiling under Intel ICPC 13.0.1.
Case study: ray-tracing scene structure
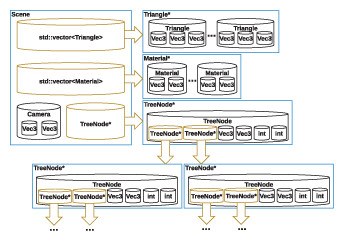
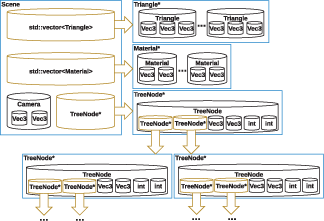
To evaluate the performance of our algorithms relative to the equivalent hand coded MPI implementations and to other libraries that offer deep copy semantics such as Boost Serialization Library (Cogswell, 2005), we used the example of deep copying a large binary-tree structure between processes in the context of a distributed ray-tracer. A 3D scene (Fig. 3) is loaded on one process, consisting of triangular meshes, cameras, materials, and a bounding volume hierarchy to help accelerate ray-triangle intersection tests.
Figure 3: Utah teapot mesh used for benchmarks.
For each experiment, a scene was loaded containing increasing numbers of the classic Utah Teapot mesh. The scene structure was then communicated using the various algorithms and the performance measured by comparing the times spent between MPI_Barrier’s before and after the communication.
Broadcast–MPI vs. MEL
For this example, just 4 lines of code calling the transport API were added to the BVH TreeNode and Scene structs (see appendix Scene Object containing MEL Deep Copy Methods) to enable both buffered and non-buffered deep copy using our algorithm.
By comparison, the hand coded MPI non-buffered (see appendix Hand coded Non-Buffered Bcast of Scene Object) method took 34 lines of code, and 70 lines of code for the MPI buffered (see appendix Hand Coded Buffered Bcast of Scene Object) algorithm (not including comments, formatting, or trailing brackets), where pointers, allocations, and object construction had to be managed manually by the programmer. Also, these implementations only handled the case of Bcast operations, while the MEL version works transparently with all operations.
Despite its generic interface and minimal syntax, our algorithm performs almost identically with hand coded MPI implementations in fewer lines of code and a fraction of the code complexity. Relevant code for this example is given in appendix Experiment 1: Broadcasting a Large Tree Structure.
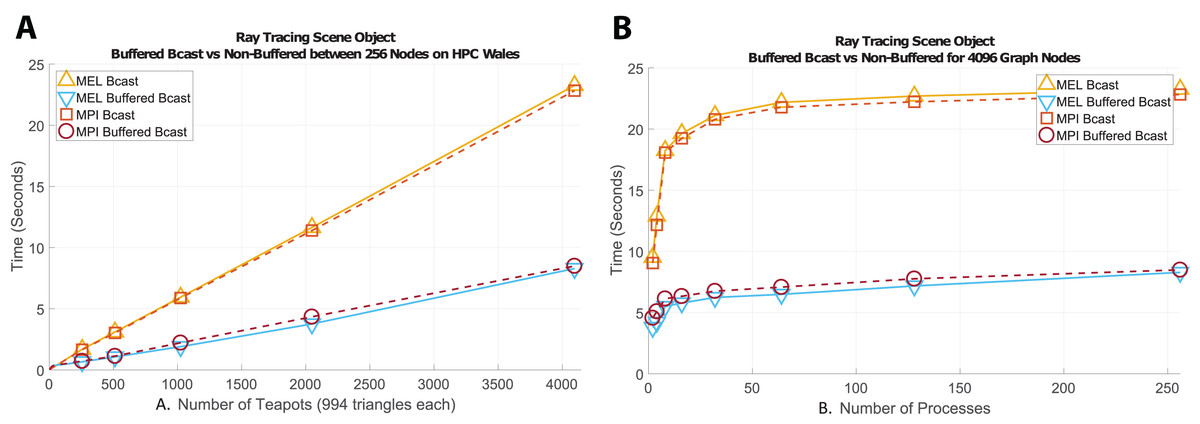
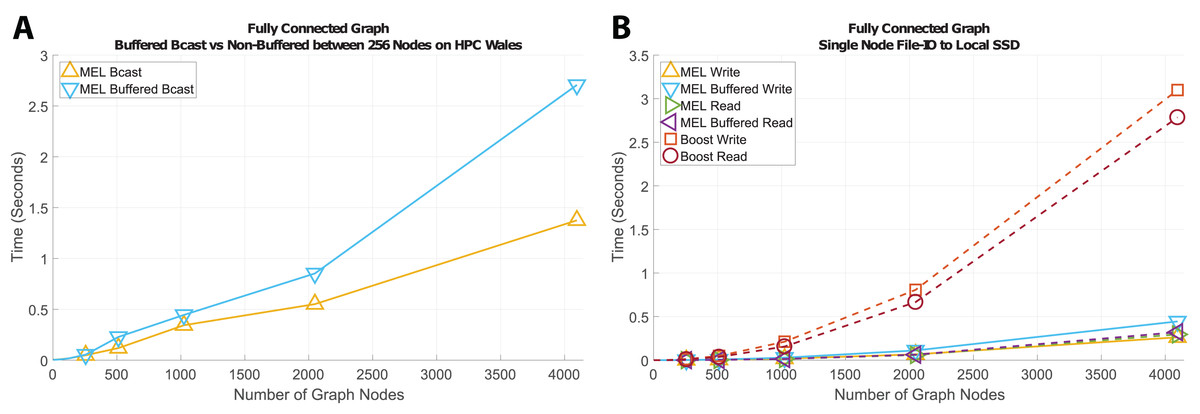
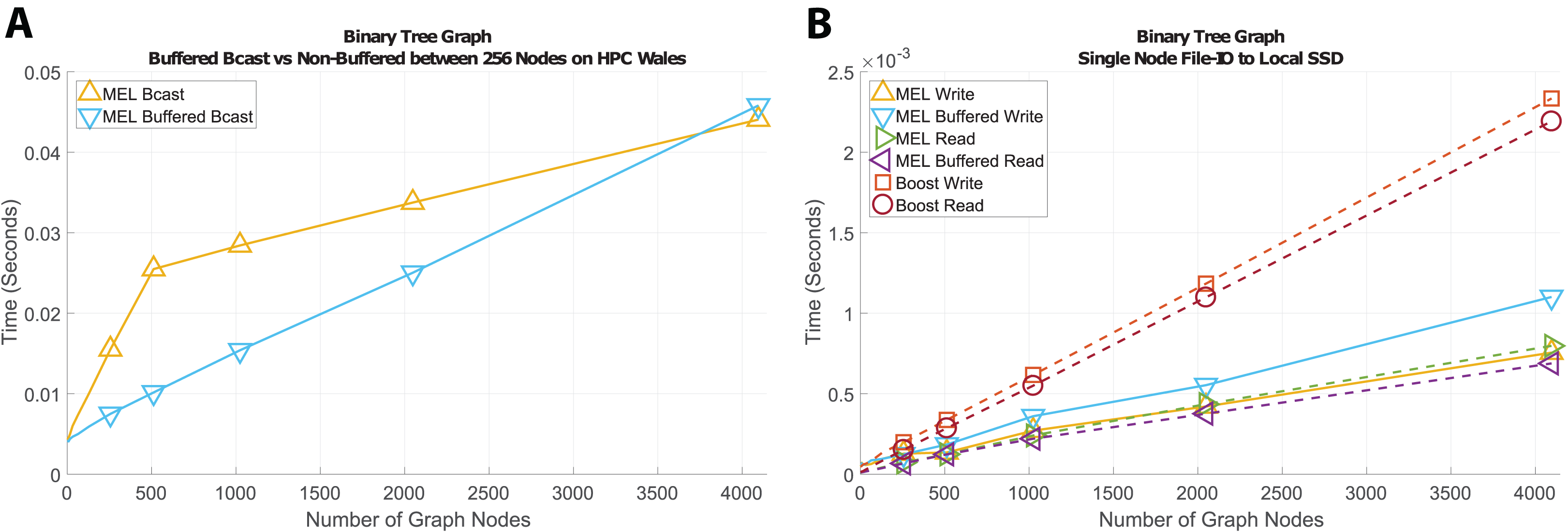
Figure 4A shows the resulting times from broadcasting increasingly larger scenes with each algorithm, between 256 nodes on HPC Wales. We can see that the buffered methods that only send a small constant number of messages between processes are faster than non-buffered methods despite the added overheads from packing and unpacking the data. The scalability of our algorithm with respect to the number of MPI processes involved in the communication is only bounded by the scalability of the transport method itself. In the case of a broadcast operation, Fig. 4B shows that varying the number processes is of the same complexity as the underlying MPI_Bcast communication (logarithmic).
Figure 4: Time comparison of algorithms broadcasting large tree structures between processes within node and on separate nodes.
MEL requires the addition of four simple lines of code which greatly accelerate programming time and vastly reduces the chance of user induced bugs.
File Write/Read–MEL vs. Boost
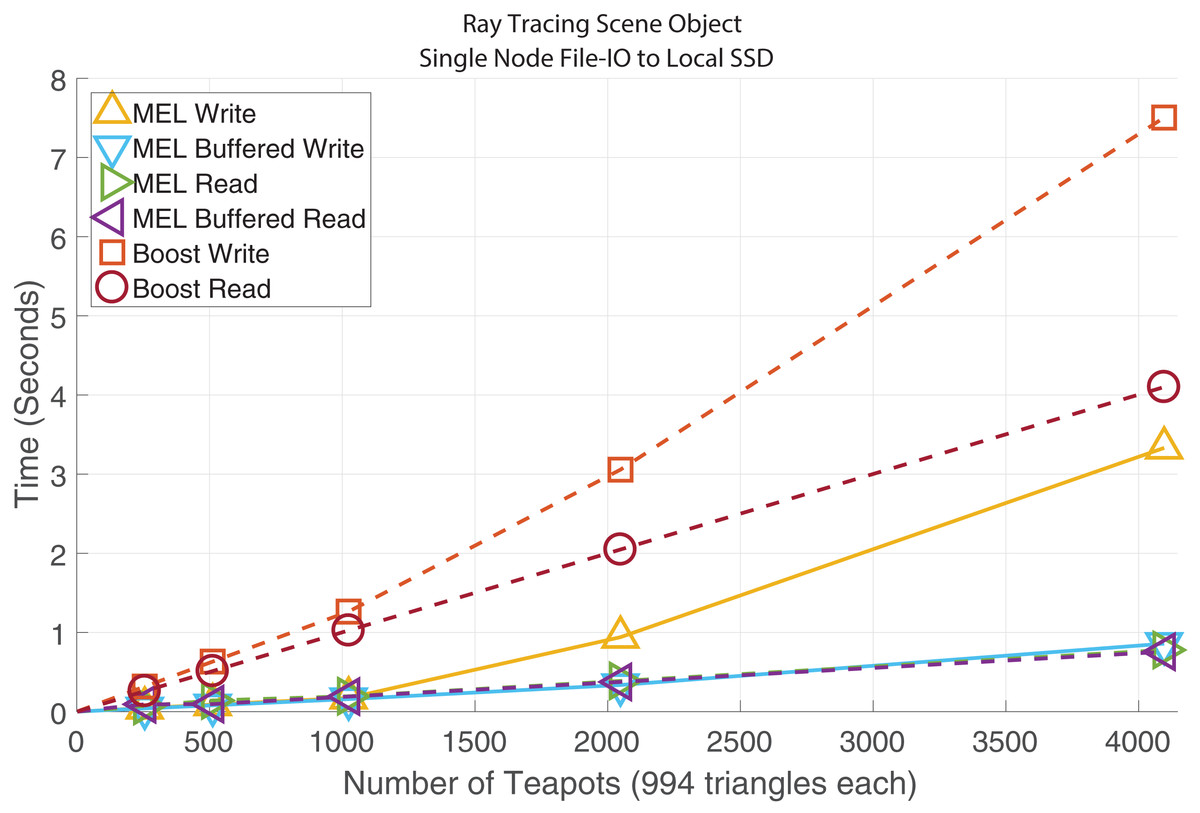
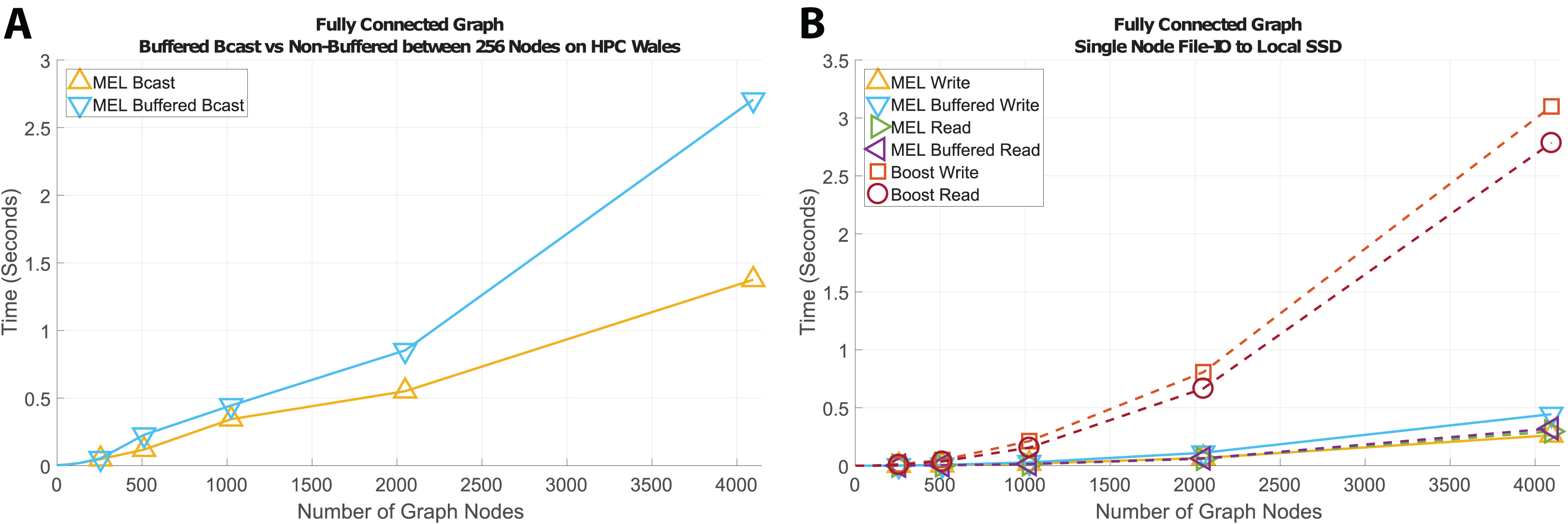
When fault tolerance is a concern one method for recovering from a failed process is to periodically cache the current state of what is being worked on to disk so that in the event of a failure the data can be reloaded on a new process (potentially on a different node) and the work continued from the point at which it was last saved. When the data needed to store the state of a process is deep we incur the same problems that arise during deep copy. MEL implements file read and write operations for both buffered and non-buffered file access, utilizing the same user defined deep copy functions needed for the broadcast, send, and receive methods. For this experiment we also compared our performance to the Boost Serialization Library which is designed for saving and restoring structured data from file.
Figure 5 shows the results of using MEL to write/read a large tree structure to or from file. Unlike with MPI communications where MEL’s buffered methods performed considerably faster than non-buffered variants due to the overheads from starting and ending network communications; with file access non-buffered reads perform almost identically to buffered methods. This is due to std::fstream’s use of an internal buffer to optimize file access, meaning that cost of starting and ending write/read operations is negligible compared to the cost of traversing the deep structure. While Boost Serialize also uses C++ streams their method of traversing the deep structure incurs significant overheads leading to poor and differing performance when reading and writing data. Finally, non-buffered writes perform slightly poorer then buffered writes due to file system having to allocate additional blocks as the file grows.
Figure 5: Time comparison of MEL to Boost Serialization Library for File Read/Write on a single node, to a within node Solid State Drive.
Case study: graphs with cycles
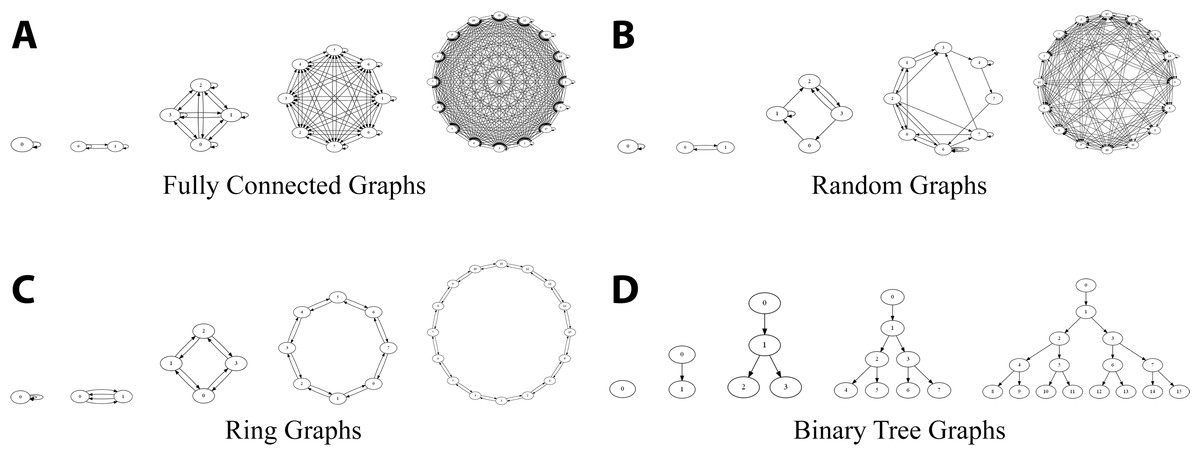
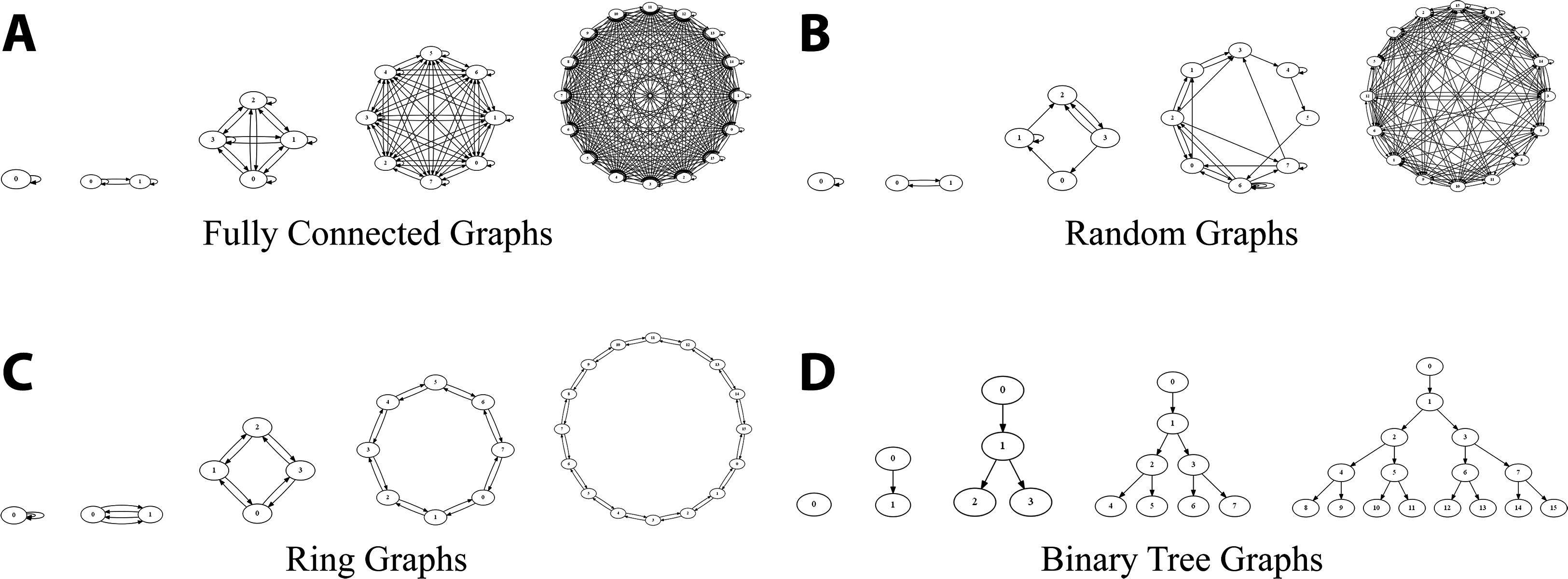
In the previous example the implementation of TreeNode was simplified by the observation that tree nodes were only pointed to from a single parent. However, in many applications multiple objects may share a common child. To show how MEL copes with structures containing pointers to shared dependents we used the example of communicating generic directed graph structures constructed in various connectivities (see Fig. 6A–6D). Relevant code for this example can be found in appendix Experiment 2: Communicating Generic Directed Graph structures.
Figure 7 shows the results for communicating fully connected graph structures of increasing size in terms of broadcast (Fig. 7A) and writing a checkpoint to file (Fig. 7B). In this example, n independent graph nodes will be traversed, each containing a list of pointers to all n nodes; during deep copy the hash-map will be queried n2 times and will grow to contain n entries. Compared to the previous broadcast example for the ray tracing case study (Section Broadcast–MPI vs. MEL) where buffered communication showed better performance, with fully connected graphs we see the opposite effect. Non-buffered communication is consistently faster when the number of shared dependents is high. Internally, shared pointers are tracked using a hash table to ensure that only distinct pointers are transported and duplicates linked correctly. Because of the overheads attached to insert and find operations on the hash table, when the number of shared dependents is high the overhead from sending separate communications for each object in the structure is small compared to that of accessing the hash table. This has the effect of making the overhead from buffering the structure into a contiguous array for transport a bottleneck for deep copy.
Figure 7: Time comparison for broadcast and file-IO operations on fully connected graph structures.
A similar trend is observed for file access, where non-buffered access is more efficient than buffered. In this example we also compare MEL to Boost Serialization library. Here shared pointer usage introduces significant overheads for Boost that our method avoids leading to significantly improved performance.
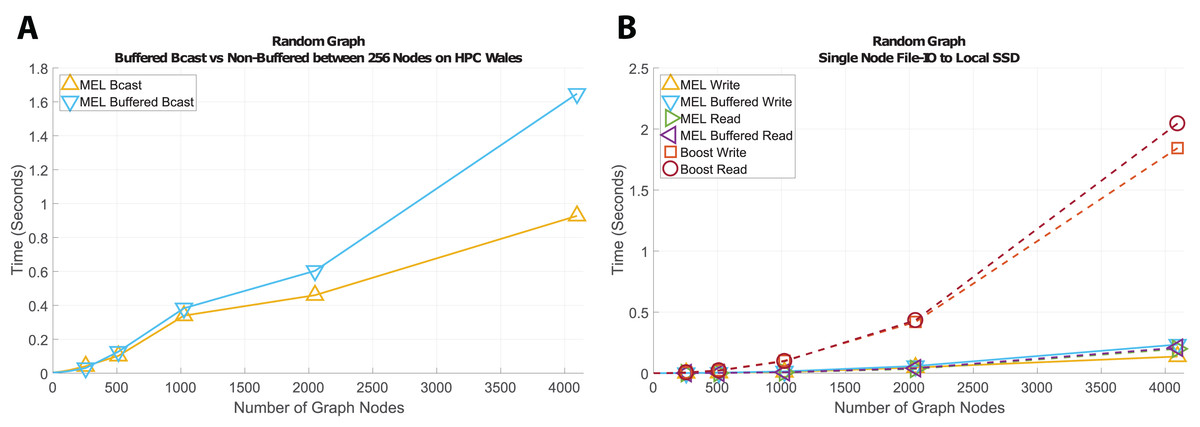
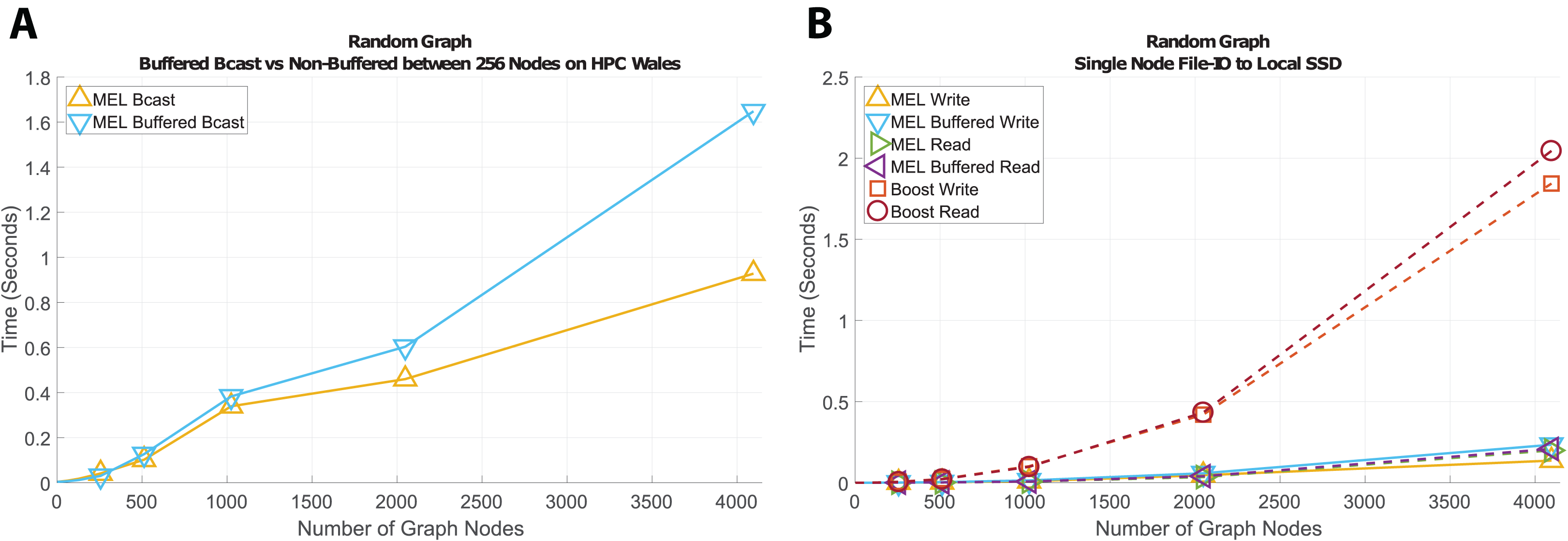
Random graph
Next we look at graphs with random connectivities. Figure 8 shows the results of communicating randomly generated graphs of different sizes for broadcasting (Fig. 8A) and writing a checkpoint to file (Fig. 8B). With this example, n independent graph nodes will be traversed, each containing a list of pointers to a random number of nodes (at least one); during deep copy the hash-map will be queried between n and n2 times and will grow to contain n entries. Again, we see that when the number of shared dependents within the structure is large non-buffered communication performs consistently better than for buffered. We also see slightly better performance than with the fully connected graphs, showing that time complexity scales linearly with the number of graph edges. For file access the same trends emerge, where our method performs considerably faster than Boost Serialization.
Figure 8: Time comparison for broadcast and file-IO operations on randomly connected graph structures.
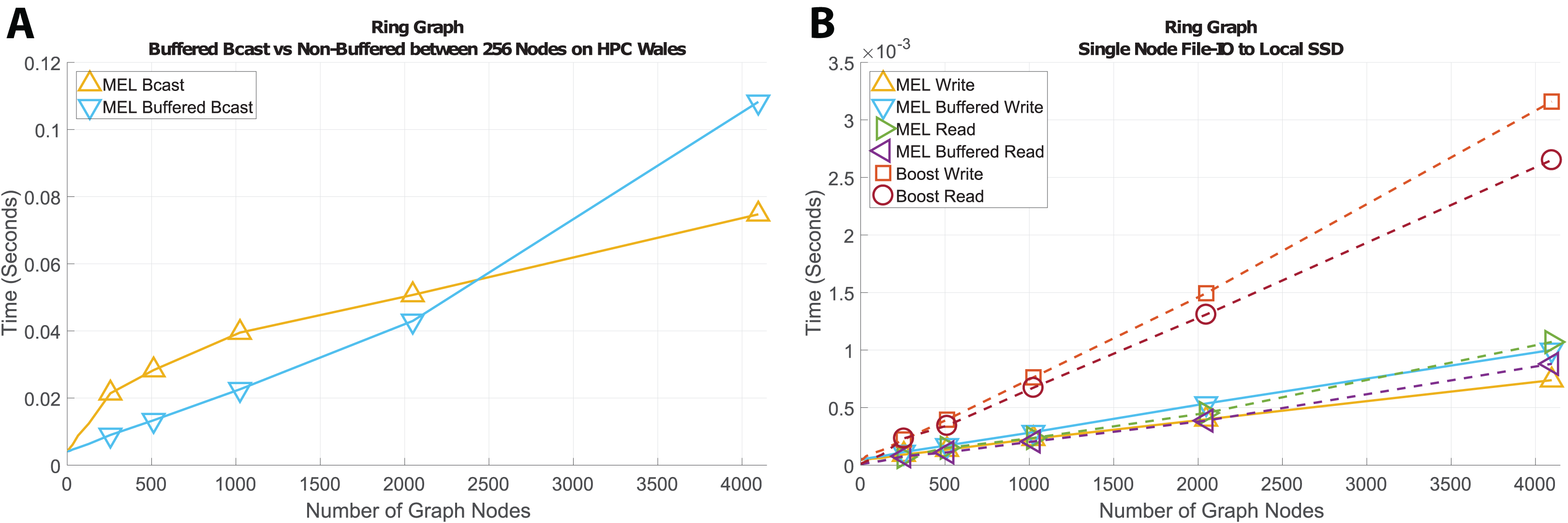
Ring graph
A ring graph can be modeled a doubly-linked list where the last element is connected back to the first element in the structure. For this example, n independent graph nodes will be traversed, each containing a list of two pointers to previous and next nodes; during deep copy the hash-map will be queried 2n times and will grow to contain n entries. Figure 9 shows the results of communicating large ring structures for broadcasting (Fig. 9A) and writing a checkpoint to file (Fig. 9B). Because the number of shared edges is small we initially see that buffered communication is faster than non-buffered as with Section Broadcast–MPI vs. MEL. As the number of graph nodes in the structure passes 2,400, the amount of time needed to buffer the structure becomes larger than the overhead associated with starting and stopping separate MPI communications making non-buffered method more efficient for larger structures. For file access, we still see that our methods perform consistently faster than Boost’s even when the number of shared dependents is low.
Figure 9: Time comparison for broadcast and file-IO operations on ring graph structures.
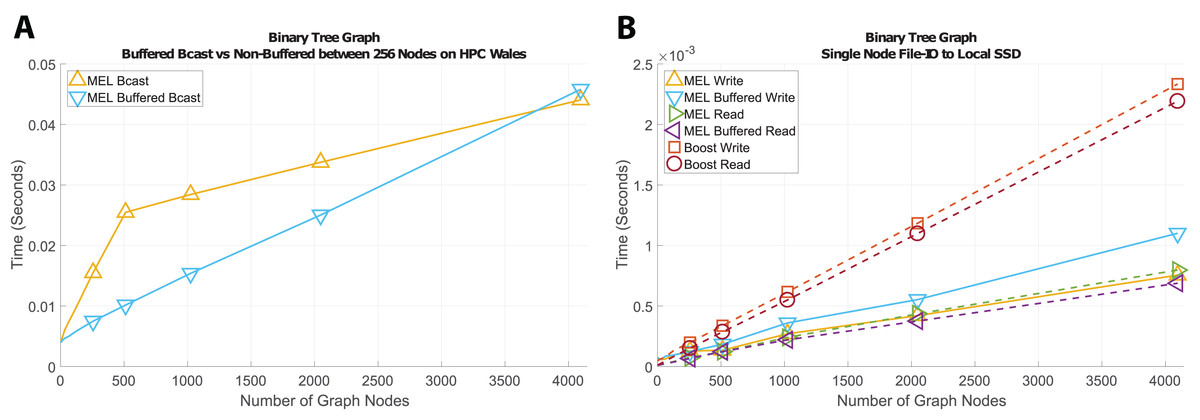
Binary tree
Finally, we look at the example of constructing a binary tree shaped graph where there are no shared dependents. The generic container does not know this, and still must use Message::packSharedPtr to transport child nodes, meaning it still incurs overheads of pointer lookup. In this example, n independent graph nodes will be traversed, each containing a list of one or two pointers to descending child nodes; during deep copy the hash-map will be queried n times and will grow to contain n entries. Figure 10 shows the results of communicating binary trees of different sizes in terms of broadcast (Fig. 10A) and writing a checkpoint to file (Fig. 10B). Similarly to communicating ring graphs, buffered network communication is significantly faster non-buffered methods until the structure becomes large enough that buffering becomes the main bottleneck.
Figure 10: Time comparison for broadcast and file-IO operations on binary tree graph structures.
For file access the opposite is true, with non-buffered file access being slightly faster than buffered. We attribute this to std::fstream’s use of internal buffering, which renders the overheads from our fully buffered method unnecessary in this use case.
Conclusions and Future Work
In this paper we have presented our implementation of deep copy semantics that encapsulates both buffered and non-buffered methods for dealing with complex structured data in the context of MPI inter-process communication and file access. Users may choose shared versions for when data structures contain cycles or faster non-shared variants for when they do not. We have shown that a generic implementation of such semantics can achieve like for like performance with hand crafted implementations while dramatically reducing code complexity and decreasing the chance for programmer error. We also demonstrate the method to be faster than utilizing Boost Serialization Library. MEL non-buffered methods provide a generic, low memory overhead, high performance (equal to hand crafted) solution to the deep copy problem.
In the future we intend to include the implementation of a non-blocking top-level interface for asynchronous deep copy, additional transport methods for communicating deep structured data to CUDA and OpenCL based accelerators, and a hash-map implementation highly optimized for pointers.
The algorithms discussed in this paper are implemented as part of the MEL, which is currently in development with the goal of creating a light weight, header only C++ wrapper around the C-style functions exposed by the MPI-3 standard, with backwards compatibility for systems where only MPI-2 is available. We plan to keep MEL in active development and hope that the research community will join us as we continue to grow the features and capabilities encompassed within the project.
"Following" is like subscribing to any updates related to a publication.
These updates will appear in your home dashboard each time you visit PeerJ.
You can also choose to receive updates via daily or weekly email digests.
If you are following multiple publications then we will send you
no more than one email per day or week based on your preferences.
Note: You are now also subscribed to the subject areas of this publication
and will receive updates in the daily or weekly email digests if turned on.
You can add specific subject areas through your profile settings.

{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}