
Predicting Hospital Readmission for Campylobacteriosis from Electronic Health Records: A Machine Learning and Text Mining Perspective

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
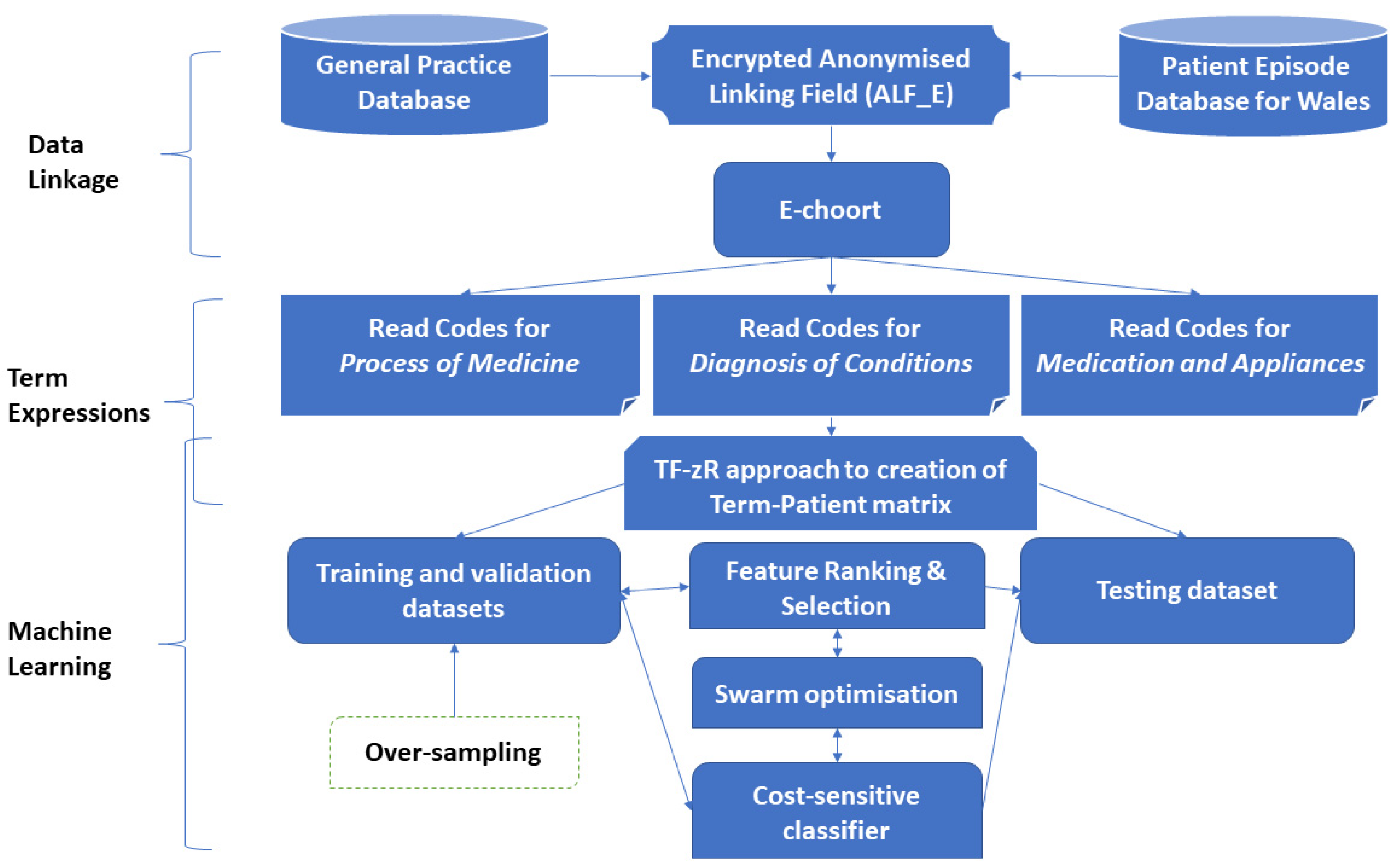
2.1. Data Collection and Linkage
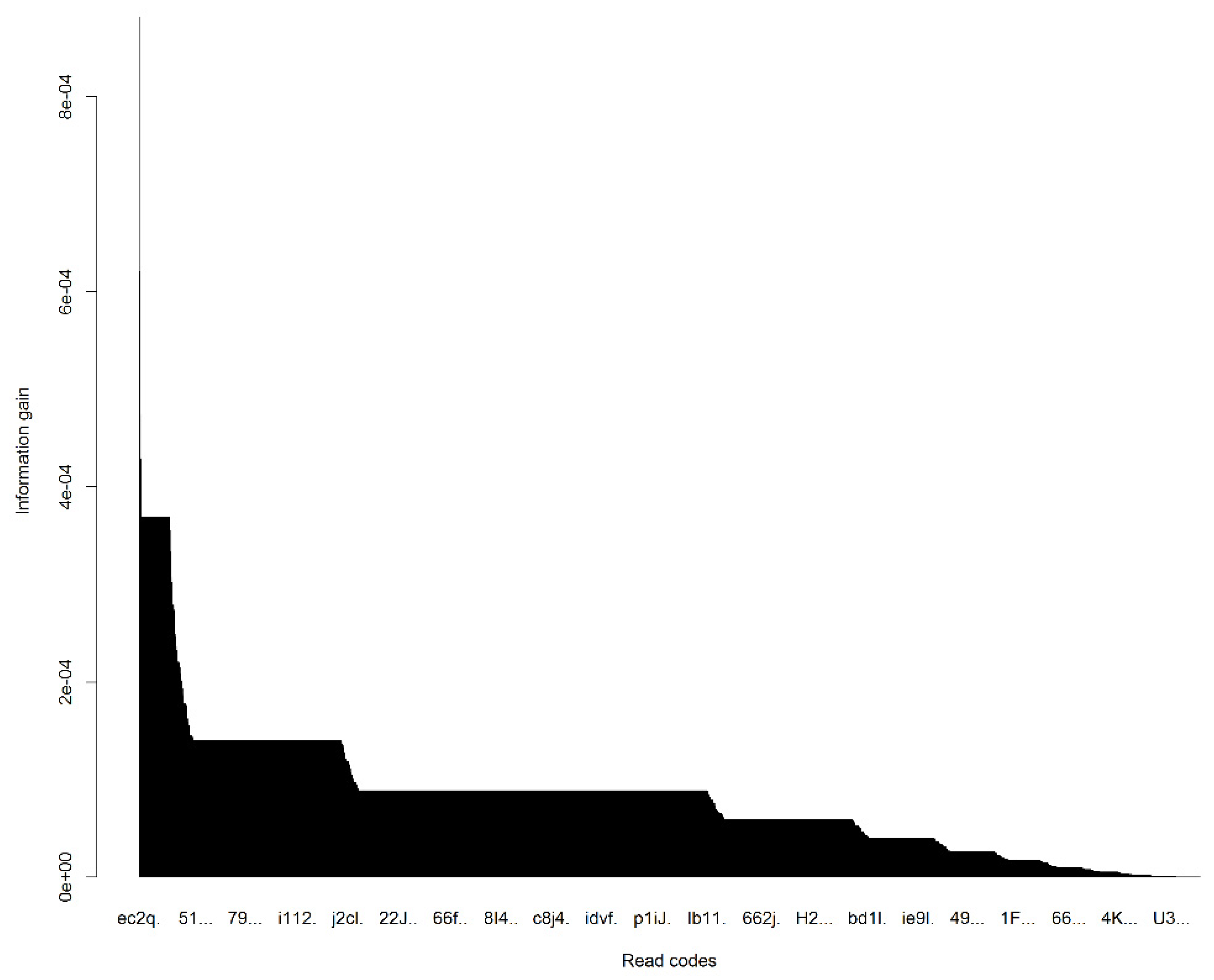
2.2. Machine Learning Approach
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. zR: Supervised Term Weighting Metric
- a = the number of patient records in the Class 1 that contains the term t.
- b = the number of patient records in the Class 1 that does not contain the term t.
- c = the number of patient records in the Class 0 that contains the term t.
- d = the number of patient records in the in Class 0 that does not contain the term t.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term t | |||
|---|---|---|---|
| Yes | No | Sum | |
| Class 1 | a | b | |
| Class 0 | c | d | |
| Sum | N | ||
Appendix A.2. TF-zR Approach to Creation of Term-Patient Matrix
References
- Ruiz-Palacios, G.M. The Health Burden of Campylobacter Infection and the Impact of Antimicrobial Resistance: Playing Chicken. Clin. Infect. Dis. 2007, 44, 701–703. [Google Scholar] [CrossRef] [PubMed]
- Eberle, K.N.; Kiess, A.S. Phenotypic and genotypic methods for typing Campylobacter jejuni and Campylobacter coli in poultry. Poult. Sci. 2012, 91, 255–264. [Google Scholar] [CrossRef] [PubMed]
- Campylobacter Attorney. Campylobacter Costs $1.3 Billion a Year in Hospitalization and Medical Costs. (n.d.-a). Available online: http://www.campylobacterblog.com/campylobacter-information/campylobacter-costs-13-billion-a-year-in-hospitalization-and-medical-costs/ (accessed on 12 February 2017).
- Food Standards Agency. Acting on Campylobacter Together. Available online: https://www.food.gov.uk/science/microbiology/campylobacterevidenceprogramme (accessed on 21 March 2017).
- Adak, G.K.; Cowden, J.M.; Nicholas, S.; Evans, H.S. The Public Health Laboratory Service national case-control study of primary indigenous sporadic cases of campylobacter infection. Epidemiol. Infect. 1995, 115, 15–22. [Google Scholar] [CrossRef] [Green Version]
- Friedman, C.R.; Hoekstra, R.M.; Samuel, M.; Marcus, R.; Bender, J.; Shiferaw, B.; Reddy, S.; Ahuja, S.D.; Helfrick, D.L.; Hardnett, F.; et al. Risk Factors for SporadicCampylobacterInfection in the United States: A Case-Control Study in FoodNet Sites. Clin. Infect. Dis. 2004, 38 (Suppl. S3), S285–S296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gallay, A.; Bousquet, V.; Siret, V.; Prouzet-Mauleon, V.; De Valk, H.; Vaillant, V.; Simon, F.; Le Strat, Y.; Mégraud, F.; Desenclos, J. Risk Factors for Acquiring SporadicCampylobacterInfection in France: Results from a National Case-Control Study. J. Infect. Dis. 2008, 197, 1477–1484. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Potter, R.C.; Kaneene, J.B.; Hall, W.N. Risk Factors for Sporadic Campylobacter jejuni Infections in Rural Michigan: A Prospective Case–Control Study. Am. J. Public Health 2003, 93, 2118–2123. [Google Scholar] [CrossRef]
- Skirrow, M.; Blaser, M. Campylobacter jejuni. In Infections of the Gastrointestinal Tract; Blaser, M.J., Smith, P.D., Ravdin, J.I., Greenberg, H.B., Guerrant, R.L., Eds.; Lippincott Williams and Wilkins: Philadelphia, PA, USA, 2002; p. 719. [Google Scholar]
- Kaakoush, N.O.; Mitchell, H.M.; Man, S.M. Role of Emerging Campylobacter Species in Inflammatory Bowel Diseases. Inflamm. Bowel Dis. 2014, 20, 2189–2197. [Google Scholar] [CrossRef]
- Gradel, K.O.; Nielsen, H.L.; Schønheyder, H.C.; Ejlertsen, T.; Kristensen, B.; Nielsen, H. Increased Short- and Long-Term Risk of Inflammatory Bowel Disease After Salmonella or Campylobacter Gastroenteritis. Gastroenterology 2009, 137, 495–501. [Google Scholar] [CrossRef]
- Jess, T.; Simonsen, J.; Nielsen, N.M.; Jørgensen, K.T.; Bager, P.; Ethelberg, S.; Frisch, M. Enteric Salmonella or Campylobacter infections and the risk of inflammatory bowel disease. Gut 2010, 60, 318–324. [Google Scholar] [CrossRef]
- Locht, H. Comparison of rheumatological and gastrointestinal symptoms after infection with Campylobacter jejuni/coli and enterotoxigenic Escherichia coli. Ann. Rheum. Dis. 2002, 61, 448–452. [Google Scholar] [CrossRef]
- Hannu, T.; Mattila, L.; Rautelin, H.; Pelkonen, P.; Lahdenne, P.; Siitonen, A.; Leirisalo-Repo, M. Campylobacter-triggered reactive arthritis: A population-based study. Rheumatology 2002, 41, 312–318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fischbach, L.A.; Nordenstedt, H.; Kramer, J.R.; Gandhi, S.; Dick-Onuoha, S.; Lewis, A.; El-Serag, H.B. The Association Between Barrett’s Esophagus and Helicobacter pylori Infection: A Meta-Analysis. Helicobacter 2012, 17, 163–175. [Google Scholar] [CrossRef] [Green Version]
- Falk, G.W. Barrett’s Esophagus: Diagnosis and Surveillance. In Practical Manual of Gastroesophageal Reflux Disease; John Wiley & Sons: Hoboken, NJ, USA, 2013; pp. 287–309. [Google Scholar] [CrossRef]
- Poropatich, K.O.; Walker, C.L.F.; Black, R. Quantifying the Association between Campylobacter Infection and Guillain-Barré Syndrome: A Systematic Review. J. Health Popul. Nutr. 2010, 28, 545–552. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drenthen, J.; Yuki, N.; Meulstee, J.; Maathuis, E.M.; Van Doorn, P.A.; Visser, G.H.; Blok, J.; Jacobs, B.C. Guillain-Barre syndrome subtypes related to Campylobacter infection. J. Neurol. Neurosurg. Psychiatry 2011, 82, 300–305. [Google Scholar] [CrossRef]
- Denneberg, T.; Friedberg, M.; Holmberg, L.; Mathiasen, C.; Nilsson, K.O.; Takolander, R.; Walder, M. Combined Plasmapheresis and Hemodialysis Treatment for Severe Hemolytic-Uremic Syndrome Following Campylobacter Colitis. Acta Paediatr. 1982, 71, 243–245. [Google Scholar] [CrossRef] [PubMed]
- Gölz, G.; Rosner, B.; Hofreuter, D.; Josenhans, C.; Kreienbrock, L.; Löwenstein, A.; Schielke, A.; Stark, K.; Suerbaum, S.; Wieler, L.H.; et al. Relevance of Campylobacter to public health—The need for a One Health approach. Int. J. Med. Microbiol. 2014, 304, 817–823. [Google Scholar] [CrossRef]
- Esan, O.B.; Perera, R.; McCarthy, N.; Violato, M.; Fanshawe, T.R. Incidence, risk factors, and health service burden of sequelae of campylobacter and non-typhoidal salmonella infections in England, 2000–2015: A retrospective cohort study using linked electronic health records. J. Infect. 2020, 81, 221–230. [Google Scholar] [CrossRef]
- Brophy, S.; Jones, K.; Rahman, M.A.; Zhou, S.-M.; John, A.; Atkinson, M.; Francis, N.; Lyons, R.A.; Dunstan, F. Incidence of Campylobacter and Salmonella Infections Following First Prescription for PPI: A Cohort Study Using Routine Data. Am. J. Gastroenterol. 2013, 108, 1094–1100. [Google Scholar] [CrossRef]
- Charlett, A.; Cowden, J.M.; Frost, J.A.; Gillespie, I.A.; Millward, J.; Neal, K.R.; O’Brien, S.J.; Painter, M.J.; Syed, Q.; Tompkins, D. Ethnicity and Campylobacter infection: A population-based questionnaire survey. J. Infect. 2003, 47, 210–216. [Google Scholar] [CrossRef]
- Gillespie, I.A.; O’Brien, S.J.; Frost, J.A.; Adak, G.K.; Horby, P.; Swan, A.V.; Painter, M.J.; Neal, K.R. A case-case comparison of Campylobacter coli and Campylobacter jejuni infection: A tool for generating hypotheses. Emerg. Infect. Dis. 2002, 8, 937–942. [Google Scholar] [CrossRef]
- Moffatt, C.R.M.; Kennedy, K.J.; Selvey, L.; Kirk, M.D. Campylobacter-associated hospitalisations in an Australian provincial setting. BMC Infect. Dis. 2021, 21, 1–10. [Google Scholar] [CrossRef]
- Vest, J.R.; Gamm, L.D.; Oxford, B.A.; Gonzalez, M.I.; Slawson, K.M. Determinants of preventable readmissions in the United States: A systematic review. Implement. Sci. 2010, 5, 88. [Google Scholar] [CrossRef] [Green Version]
- Morris, J. Emergency Readmissions: Trends in Emergency Readmissions to Hospital in England. Nuffield Trust. Available online: http://www.qualitywatch.org.uk/blog/emergency-readmissions-trends-emergency-readmissions-hospital-england# (accessed on 20 September 2018).
- Scallan Walter, E.J.; Crim, S.M.; Bruce, B.B.; Griffin, P.M. Incidence of Campylobacter-Associated Guillain-Barré Syndrome Estimated from Health Insurance Data. Foodborne Pathog. Dis. 2020, 17, 23–28. [Google Scholar] [CrossRef]
- Cotter, P.E.; Bhalla, V.K.; Wallis, S.J.; Biram, R.W.S. Predicting readmissions: Poor performance of the LACE index in an older UK population. Age Ageing 2012, 41, 784–789. [Google Scholar] [CrossRef] [Green Version]
- Van Walraven, C.; Dhalla, I.A.; Bell, C.; Etchells, E.; Stiell, I.G.; Zarnke, K.; Austin, P.C.; Forster, A.J. Derivation and validation of an index to predict early death or unplanned readmission after discharge from hospital to the community. Can. Med. Assoc. J. 2010, 182, 551–557. [Google Scholar] [CrossRef] [Green Version]
- van Walraven, C.; Wong, J.; Hawken, S.; Forster, A.J. Comparing methods to calculate hospital-specific rates of early death or urgent readmission. Can. Med. Assoc. J. 2012, 184, E810–E817. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Billings, J.; Dixon, J.; Mijanovich, T.; Wennberg, D. Case finding for patients at risk of readmission to hospital: Development of algorithm to identify high risk patients. BMJ 2006, 333, 327. [Google Scholar] [CrossRef] [Green Version]
- Department of Health. Payment by Results Guidance for 2012–2013. Gateway Reference 17250; Department of Health: London, UK, 2012.
- Centers for Medicare and Medicaid Services. Readmissions Reduction Program (HRRP). Available online: https://www.cms.gov/Medicare/Medicare-Fee-for-Service-Payment/AcuteInpatientPPS/Readmissions-Reduction-Program.html (accessed on 20 September 2017).
- What Do the Numbers Say about Emergency Readmissions to Hospital? Health Watch. Available online: https://www.healthwatch.co.uk/sites/healthwatch.co.uk/files/20171025_what_do_the_numbers_say_about_emergency_readmissions_final_0.pdf (accessed on 20 September 2018).
- Eberhart-Phillips, J.; Walker, N.; Garrett, N.; Bell, D.; Sinclair, D.; Rainger, W.; Bates, M. Campylobacteriosis in New Zealand: Results of a case-control study. J. Epidemiol. Community Health 1997, 51, 686–691. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, L.C.; Cowden, J.M.; Wheeler, J.G.; Sethi, D.; Wall, P.G.; Cumberland, P.; Tompkins, D.S.; Hudson, M.J.; Roberts, J.A.; Roderick, P.J. The study of infectious intestinal disease in England: Risk factors for cases of infectious intestinal disease with Campylobacter jejuni infection. Epidemiol. Infect. 2000, 127, 185–193. [Google Scholar] [CrossRef] [PubMed]
- Lineback, C.M.; Garg, R.; Oh, E.; Naidech, A.M.; Holl, J.L.; Prabhakaran, S. Prediction of 30-Day Readmission After Stroke Using Machine Learning and Natural Language Processing. Front. Neurol. 2021, 12, 649521. [Google Scholar] [CrossRef]
- Arnaud, E.; Elbattah, M.; Gignon, M.; Dequen, G. Deep Learning to Predict Hospitalization at Triage: Integration of Structured Data and Unstructured Text. In Proceedings of the 2020 IEEE International Conference on Big Data, (Big Data), Atlanta, GA, USA, 10–13 December 2020. [Google Scholar] [CrossRef]
- Ford, D.V.; Jones, K.H.; Verplancke, J.-P.; Lyons, R.A.; John, G.; Brown, G.; Brooks, C.J.; Thompson, S.; Bodger, O.; Couch, T.; et al. The SAIL Databank: Building a national architecture for e-health research and evaluation. BMC Health Serv. Res. 2009, 9, 157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lyons, R.A.; Jones, K.H.; John, G.; Brooks, C.J.; Verplancke, J.-P.; Ford, D.V.; Brown, G.; Leake, K. The SAIL databank: Linking multiple health and social care datasets. BMC Med. Inform. Decis. Mak. 2009, 9, 3. [Google Scholar] [CrossRef] [Green Version]
- ONS. Rural and Urban Area Definition Metadata. Available online: https://www.ons.gov.uk (accessed on 18 November 2016).
- Zhou, S.-M.; Fernandez-Gutierrez, F.; Kennedy, J.; Cooksey, R.; Atkinson, M.; Denaxas, S.; Siebert, S.; Dixon, W.; O’Neill, T.W.; Choy, E.; et al. Defining Disease Phenotypes in Primary Care Electronic Health Records by a Machine Learning Approach: A Case Study in Identifying Rheumatoid Arthritis. PLoS ONE 2016, 11, e0154515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, S.-M.; Lyons, R.A.; Bodger, O.G.; John, A.; Brunt, H.; Jones, K.; Gravenor, M.B.; Brophy, S. Local Modelling Techniques for Assessing Micro-Level Impacts of Risk Factors in Complex Data: Understanding Health and Socioeconomic Inequalities in Childhood Educational Attainments. PLoS ONE 2014, 9, e113592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feldman, R.; Sanger, J. The text mining handbook: Advanced approaches in analyzing unstructured data. Imagine 2007, 34, 410. [Google Scholar] [CrossRef]
- Zhou, S.-M.; Rahman, M.A.; Atkinson, M.; Brophy, S. Mining textual data from primary healthcare records: Automatic identification of patient phenotype cohorts. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 3621–3627. [Google Scholar] [CrossRef]
- Lu, H.; Xu, Y.; Ye, M.; Yan, K.; Gao, Z.; Jin, Q. Learning misclassification costs for imbalanced classification on gene expression data. BMC Bioinform. 2019, 20, 681. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M. Data Mining: Practical Machine Learning Tools and Techniques. In Complementary Literature None, 3rd ed.; Elsevier: New York, NY, USA, 2011. [Google Scholar]
- Zhou, S.-M.; Lyons, R.A.; Bodger, O.; Demmler, J.C.; Atkinson, M.D. SVM with entropy regularization and particle swarm optimization for identifying children’s health and socioeconomic determinants of education attainments using linked datasets. In Proceedings of the International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010. [Google Scholar] [CrossRef]
- Koehler, B.E.; Richter, K.M.; Youngblood, L.; Cohen, B.A.; Prengler, I.D.; Cheng, D.; Masica, A.L. Reduction of 30-day postdischarge hospital readmission or emergency department (ED) visit rates in high-risk elderly medical patients through delivery of a targeted care bundle. J. Hosp. Med. 2009, 4, 211–218. [Google Scholar] [CrossRef]
- Zhou, S.-M.; Gan, J. Constructing L2-SVM-Based Fuzzy Classifiers in High-Dimensional Space With Automatic Model Selection and Fuzzy Rule Ranking. IEEE Trans. Fuzzy Syst. 2007, 15, 398–409. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]





| Non-Readmission | Readmission | |
|---|---|---|
| Number of admitted patients | 11,944 | 1062 |
| Average age of admissions | 43.0 (SD = 22.1) | 51.8 (SD = 22.3) |
| Percentage of male admissions | 49.9% | 55.6% |
| Percentage of admissions in most affluent | 22.4% | 21.7% |
| Percentage of admission in most deprived | 17.6% | 18.7% |
| Percentage of admissions in rural domains * | 37.2% | 37.7% |
| Variable Name | Description |
|---|---|
| Male | Gender |
| AGE_A21–25 | Age group: 21~25 years old |
| TOWSEND_Q1 | Townsend quintile band 1 |
| TOWSEND_Q4 | Townsend quintile band 4 |
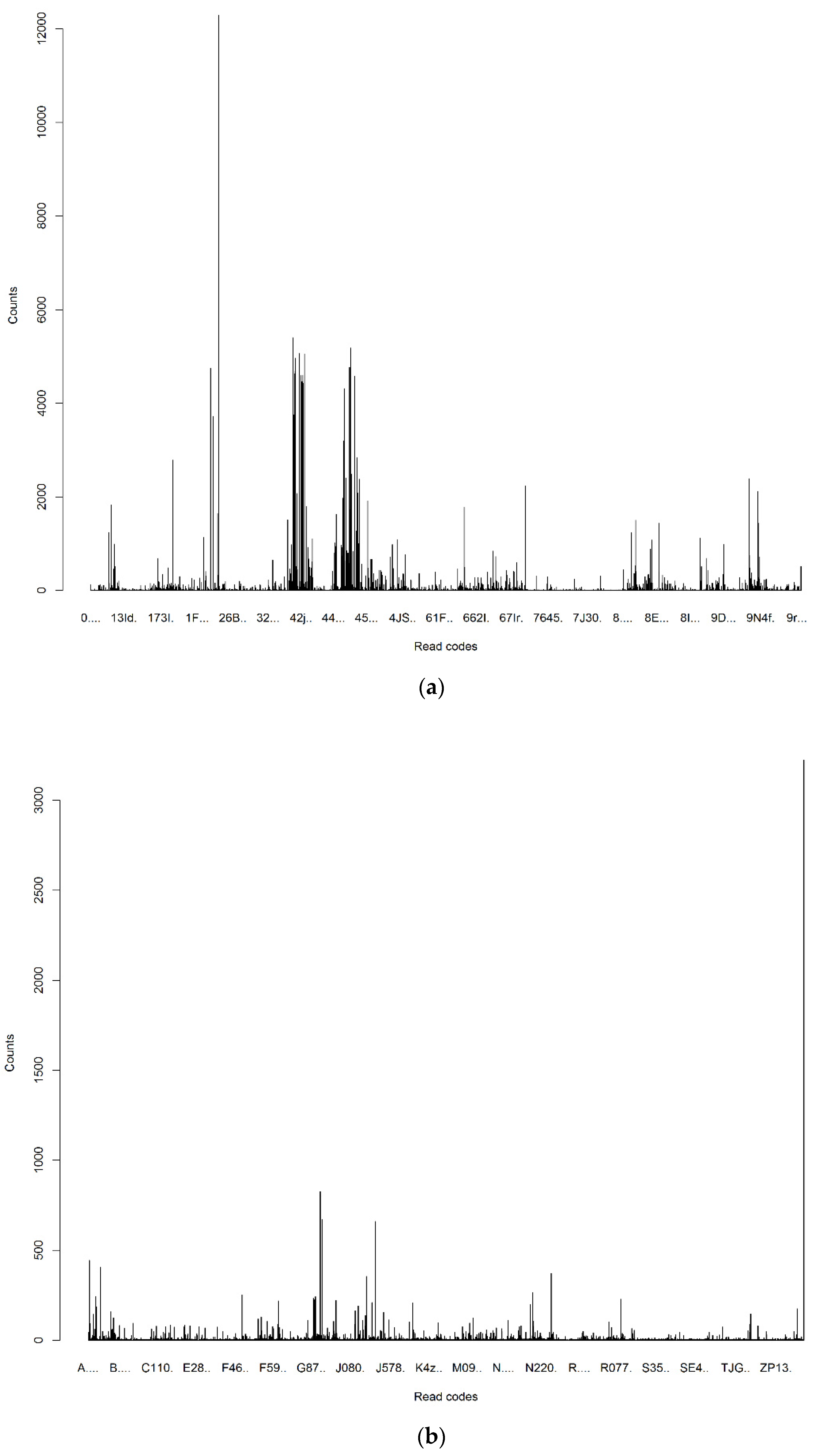
| 67E.. | Foreign travel advice |
| 8B311 | Medication given |
| 67H.. | Lifestyle counselling |
| 9.... | Administration |
| 8H7.. | Other referral |
| 7G300 | Excision of nail bed |
| R0901 | Abdominal colic |
| K3108 | Breast infection |
| S89z. | Other open wounds NOS |
| K15.. | Cystitis |
| H170. | Allergic rhinitis due to pollens |
| H037. | Recurrent acute tonsillitis |
| A53.. | Herpes zoster |
| N05.. | Osteoarthritis and allied disorders |
| Ayu03 | Salmonella infection, unspecified |
| F501. | Infective otitis externa |
| F504. | Impacted cerumen (wax in ear) |
| N2410 | Myalgia unspecified |
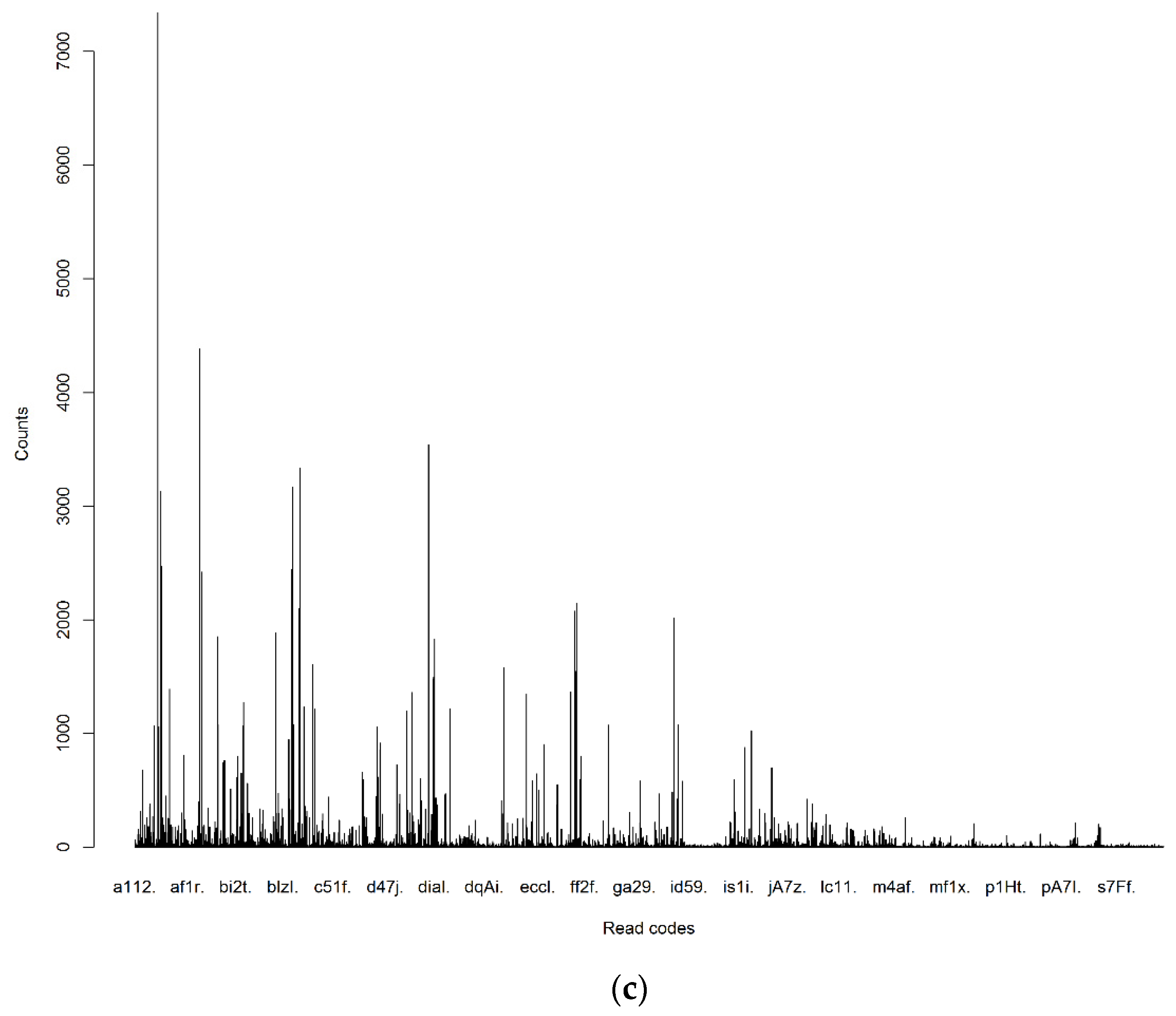
| dian. | Paracetamol+codeine phosphate 500 mg/30 mg tablets |
| ka91. | Celluvisc 1% single-use eye drops |
| da7Z. | Venaxx XL 75 mg m/r capsules |
| dher. | Prochlorperazine 5 mg tablets |
| c13M. | Ventolin 200 micrograms Accuhaler |
| bs18. | Warfarin sodium 3 mg tablets |
| a6g2. | Heliclear triple pack |
| k3g1. | Fusidic acid 1% eye drops |
| e91E. | Erythromycin 125 mg/5mL sugar free suspension |
| c61z. | Beclometasone dipropionate 100 micrograms inhaler |
| da61. | Paroxetine 20 mg tablets |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.-M.; Lyons, R.A.; Rahman, M.A.; Holborow, A.; Brophy, S. Predicting Hospital Readmission for Campylobacteriosis from Electronic Health Records: A Machine Learning and Text Mining Perspective. J. Pers. Med. 2022, 12, 86. https://doi.org/10.3390/jpm12010086
Zhou S-M, Lyons RA, Rahman MA, Holborow A, Brophy S. Predicting Hospital Readmission for Campylobacteriosis from Electronic Health Records: A Machine Learning and Text Mining Perspective. Journal of Personalized Medicine. 2022; 12(1):86. https://doi.org/10.3390/jpm12010086
Chicago/Turabian StyleZhou, Shang-Ming, Ronan A. Lyons, Muhammad A. Rahman, Alexander Holborow, and Sinead Brophy. 2022. "Predicting Hospital Readmission for Campylobacteriosis from Electronic Health Records: A Machine Learning and Text Mining Perspective" Journal of Personalized Medicine 12, no. 1: 86. https://doi.org/10.3390/jpm12010086